# 103.2 - Procesar secuencias de texto usando filtros
Importancia
2
Descripción
El candidato debe saber aplicar filtros a secuencias de texto.
#### *Áreas de conocimiento clave:*
* Enviar archivos de texto y flujos de salida a través de filtros de utilidades de texto para modificar la salida usando comandos UNIX estándar incluidos en el paquete GNU textutils.
### *Contenidos*
### Outputs y pipes
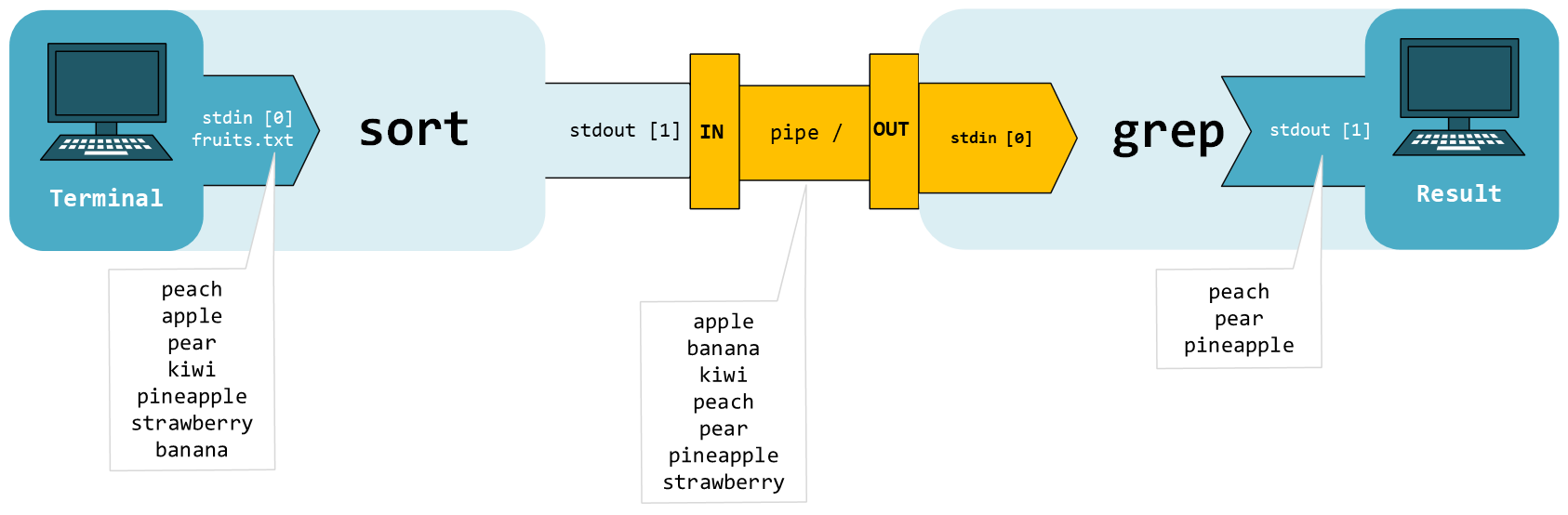
Una forma importante de hacer que los programas funcionen juntos es a través de piping y redirections. Casi todos sus programas de manipulación de texto obtendrán texto de una entrada estándar (stdin), lo enviarán a una salida estándar (stdout) y enviarán eventuales errores a una salida de error estándar (stderr).
* A menos que especifique lo contrario, la entrada estándar será la que escriba en su teclado (el programa lo leerá después de presionar la tecla Enter).
* Los canales de comunicación también son accesibles a través de los dispositivos especiales `/dev/stdin`, `/dev/stdout` y `/dev/stderr`.
En el diagrama se ven el nombre de los canales y el número de referencia. Por cada entrada se producen dos salidas, el output normal y el de error.
En la terminal, teclea `cat` y luego presiona la tecla Enter. Luego teclea un texto al azar.
cat
#This is a test
This is a test
#Hey!
Hey!
#It is repeating everything I type!
It is repeating everything I type!
#(I will hit ctrl+c so I will stop this nonsense)
(I will hit ctrl+c so I will stop this nonsense)
^C
{% hint style="info" %}
Un error común es pensar que `cat` sirve para "leer" archivos, si vamos a la entrada del manual veremos que no es así (el término proviene de “concatenate”), este en realidad nos sirve para concatenar palabras, lo veremos más adelante.
{% endhint %}
Como se demostró anteriormente, si no especifica de dónde se debe leer cat, leerá desde la entrada estándar (lo que escribimos `stdin`) y enviará lo que lea a su ventana de terminal (su salida estándar `stdout`). Ahora intenta lo siguiente:
```bash
cat > mytextfile
#This is a test
#I hope cat is storing this to mytextfile as I redirected the output
#I will hit ctrl+c now and check this ^C
cat mytextfile
#This is a test
#I hope cat is storing this to mytextfile as I redirected the output
#I will hit ctrl+c now and check this ^C
```
El > (mayor que) indica a `cat` que dirija su salida al archivo `mytextfile`, no a la salida estándar (`stdout`). Ahora intenta esto:
cat mytextfile > mynewtextfile
cat mynewtextfile
#This is a test
#I hope cat is storing this to mytextfile as I redirected the output
#I will hit ctrl+c now and check this
Estolo que hace es copiar `mytextfile` a `mynewtextfile`. En realidad, puede verificar que estos dos archivos tengan el mismo contenido realizando un diff:
```bash
diff mynewtextfile mytextfile
```
Como no hay salida, los archivos son iguales. Ahora intente con el operador de redireccionamiento anexado (>>):
```
echo 'This is my new line' >> mynewtextfile
diff mynewtextfile mytextfile 4d3 < This is my new line
```
Hasta ahora hemos usado redirecciones para crear y manipular archivos. También podemos usar tuberías (representadas por el símbolo |) para redirigir la salida de un programa a otro. Encontremos las líneas donde se encuentra la palabra “*this*”:
```bash
cat mytextfile | grep this
#I hope cat is storing this to mytextfile as I redirected the output
#I will hit ctrl+c now and check this
cat mytextfile | grep -i this
#This is a test
#I hope cat is storing this to mytextfile as I redirected the output
#I will hit ctrl+c now and check this
```
Ahora hemos canalizado la salida de cat a otro comando: `grep`. Nota que cuando ignoramos mayúsculas y minúsculas (usando la opción `-i`) obtenemos una línea extra como resultado.
A continuación tenemos otro ejemplo más complejo de como funciona:
```bash
find / -type f -name fstab 1>match.txt 2>/dev/null
```
Este comando:
* Busca en el directorio raiz `/` de tipo archivo "`type file`" que coincidan con el nombre "`fstab`".
* El output 1 (`stdout`) se guardara en un archivo llamado "`match.txt`".
* El otuput 2 (`stderr`) se enviará al "agujero negro" de linux, o sea, no mostrará los errores, se podrían enviar a otro archivo también.
De la misma forma se podría añadir más información al archivo simplemente:
```bash
find / -type f -name "screen" 1>>match.txt
```
Esto sobrescribirá el archivo con la nueva información.
También podemos realizar la versión inversa, pasarle un archivo como input a un comando a través del símbolo de menor que:
```bash
sudo mysql -u root fruits.txt
#apple
#peach
#pear
#kiwi
#pineapple
#strawberry
#banana
sort fruits.txt | grep ea
#peach
#pear
#pineapple
```
Esto lo que hace es ordenar todas las líneas (frutas) alfabéticamente y seleccionar aquellas que coincida las dos vocales.
Diagrama de flujo
### Ver un archivo paginado
Ya hemos visto como `cat` puede leer la información de un archivo pero en archivos muy grandes no es recomendable usarlo, para ello tenemos utilidades como `less`:
```bash
sudo less /var/log/syslog
```
Esta utilidad es una simplificación de `vi` (que veremos mas adelante) ya que genera su propia *shell child* y que nos permite movernos por el archivo con las teclas o buscar palabras con `/nombre`, para salir escribe `q`.
La otra utilidad es `more` que muestra todo el contenido de un fichero en una sola pantalla, pagina el contenido pero solo permite ir hacia delante o atrás.
```bash
sudo more /var/log/syslog
```
Otra forma de leer los archivos es formateándolos al ancho deseado lo cual nos puede servir para establecer matrices por ejemplo. `fmt` lee la salida del fichero ajustado a un ancho determinado:
```bash
sudo fmt /var/log/syslog
#Podemos ajustar el ancho con:
sudo fmt -w 30 /var/log/syslog
```
{% hint style="info" %}
Recuerda que, tal y como hemos mencionado anteriormente, los espacios también son símbolos y cuentan.
{% endhint %}
***
### Ordenar archivos
El comando `sort` ayuda a organizar líneas de texto ordenándolas de distintas maneras, ya sea que trabajes con listas, tablas o archivos de registro, este comando le permite organizar datos según orden alfabético, valores numéricos, columnas específicas o incluso criterios personalizados. En este resumen, exploraremos cómo usar `sort` de manera efectiva, destacando las opciones más comunes y brindando ejemplos prácticos.
#### Opciones de comando `sort` comunes
A continuación, se muestra un resumen rápido de las opciones más comunes del comando `sort` para realizar diferentes tipos de clasificación:
* `-n` : ordena numéricamente, lo que lo hace ideal para listas de números.
* `-r` : ordena en orden inverso, mostrando los resultados del más grande al más pequeño (o en orden alfabético inverso para el texto).
* `-k` : ordena según un campo o columna específicos, útil para datos estructurados como archivos CSV.
* `-u` : elimina líneas duplicadas en la salida ordenada, lo que garantiza resultados únicos.
* `-f` : ignora mayúsculas y minúsculas al ordenar, tratando las letras mayúsculas y minúsculas como equivalentes.
* `-o` : Dirige la salida ordenada a un archivo en lugar de a la terminal.
* `-t` : le permite especificar un delimitador personalizado, como comas en archivos CSV, para la clasificación basada en campos.
#### Ejemplos prácticos del uso `sort`
Veamos algunas operaciones comunes que puedes realizar usando el comando `sort` :
#### 1. Ordenar el texto alfabéticamente
El comportamiento predeterminado de `sort` es ordenar las líneas alfabéticamente. A continuación, se muestra un ejemplo:
```bash
sort file.txt
```
Este comando mostrará el contenido del `file.txt` en orden alfabético.
#### 2. Ordenar números
Si desea ordenar números en lugar de texto, deberá usar la opción `-n` . Ordenar valores numéricos es diferente a ordenar texto porque considera la magnitud del número:
```bash
sort -n numbers.txt
```
Esto ordenará el archivo `numbers.txt` según el valor numérico de cada línea.
Sin esta opción, los números se ordenarían como texto, lo que podría no dar el resultado deseado (por ejemplo, tratar "10" como menor que "2"). Este comando ordena según el valor numérico de cada línea.
#### 3. Ordenación inversa
A veces, es posible que desee ver los datos ordenados en orden inverso. Simplemente agregue la opción `-r` para invertir el orden:
```bash
sort -r file.txt
```
Esto se aplica tanto al texto como a los números, dependiendo de sus datos.
#### 4. Ordenar por un campo o columna específicos
Al trabajar con datos estructurados como CSV o archivos separados por tabulaciones, puede ordenar en función de un campo en particular utilizando la opción `-k` . Por ejemplo, para ordenar por la segunda columna:
```bash
sort -k 2 file.txt
```
Para los archivos CSV donde las columnas están separadas por comas, combine `-k` con la opción `-t` para especificar el delimitador (por ejemplo, una coma para archivos CSV):
```bash
sort -t ',' -k 2 file.csv
```
Este comando ordena el archivo CSV según los valores de la segunda columna.
#### 5. Eliminar duplicados durante la clasificación
Si sus datos contienen líneas duplicadas, puede eliminarlas mientras ordena agregando la opción `-u` :
```bash
sort -u file.txt
```
Esto le proporciona datos ordenados con solo líneas únicas.
#### 6. Ordenación sin distinción entre mayúsculas y minúsculas
Si desea realizar una ordenación que no distinga entre mayúsculas y minúsculas (por ejemplo, para tratar "Apple" y "apple" como lo mismo), utilice la opción `-f` :
```bash
sort -f file.txt
```
#### 7. Guardar la salida ordenada en un archivo
También puede guardar la salida ordenada directamente en otro archivo usando la opción `-o` :
```bash
sort file.txt -o sorted_output.txt
```
Este comando ordena el contenido de `file.txt` y escribe el resultado ordenado en `sorted_output.txt` .
***
### Obtener una parte de un archivo de texto
Si solo necesitamos revisar el inicio o el final de un archivo, hay otros métodos como el comando `head` se usa para leer las primeras diez líneas de un archivo de manera predeterminada, y el comando `tail` se usa para leer las últimas diez líneas de un archivo de manera predeterminada. Ahora intente:
{% code overflow="wrap" %}
```bash
sudo head /var/log/syslog
sudo tail /var/log/syslog
#Para ilustrar esto podemos usar los siguientes comandos:
sudo head /var/log/syslog | wc -l
sudo tail /var/log/syslog | wc -l
#Esto devolverá "10" ya que el comando wc cuenta las palabras pero con -l cuenta las lineas
#De la misma forma podemos intentar esto:
sudo head /var/log/syslog | nl
sudo tail /var/log/syslog | nl
#Lo cual añadirá el numero de la linea al lado.
#Para limitar la salida tambien se puede determinar el número de linias con:
sudo head -n 5 /var/log/syslog
sudo tail -n 12 /var/log/syslog
```
{% endcode %}
Ejemplo para practicar
**Archivo `datos.csv` de ejemplo:**
```csv
ID,Nombre,Edad,País
1,Juan,25,México
2,Ana,30,Argentina
3,Luis,28,España
4,Carla,22,Chile
5,Pedro,35,Perú
6,María,30,México
7,Angel,24,España
8,Aline,45,Chile
9,Eduardo,79,México
10,Galina,40,Perú
```
***
#### ➜ Ordenar por la columna **Edad** (números):
```bash
sort -t ',' -k 3 -n datos.csv
```
* `-t,` → Indica que el delimitador es la coma.
* `-k3` → Ordena por la **tercera columna** (Edad).
* `-n` → Orden numérico.
#### ➜ Ordenar alfabéticamente por **País**:
```bash
sort -t, -k4 datos.csv
```
#### ➜ Filtrar personas de México:
```bash
grep "México" datos.csv
```
#### ➜ Filtrar las filas que contienen "30" (Edad):
```bash
grep ",30," datos.csv
```
* Uso de `,30,` para evitar confundir con otro número como `130`.
#### ➜ Contar el **número de filas** en el archivo:
```bash
wc -l datos.csv
```
* Muestra cuántas líneas tiene el CSV.
#### ➜ Contar el **número total de palabras**:
```bash
wc -w datos.csv
```
#### ➜ Numerar todas las filas:
```bash
nl datos.csv
```
#### ➜ Numerar desde la fila 2 (omitiendo la cabecera):
```bash
tail -n +2 datos.csv | nl
```
#### ➜ Mostrar las **primeras 3 filas**:
```bash
head -n 3 datos.csv
```
#### ➜ Mostrar las **últimas 3 filas**:
```bash
tail -n 3 datos.csv
```
***
#### ➜ Filtrar las personas de México, ordenarlas por edad y numerarlas:
```bash
grep "México" datos.csv | sort -t ',' -k 3 -n | nl
```
***
### Modificación de textos
`uniq` elimina las líneas adyacentes consecutivas por lo que muchas veces se usa con `sort` para eliminar líneas repetidas. Usando de ejemplo un listado de frutas con líneas repetidas debería devolvernos un listado de las frutas en general con el siguiente:
```bash
sort fruits.txt | uniq
```
{% hint style="info" %}
Este comando realiza lo mismo que `sort -u`
{% endhint %}
`tr` traduce caracteres en el sentido que reemplaza y modifica la salida pero no el archivo. Se puede usar para cosas como poner las mayúsculas en minúsculas o traducir los espacios por comas, etc. Se trata de un comando muy útil en el tratamiento de textos.
Vamos a ver algunos ejemplos:
{% code fullWidth="true" %}
```bash
cat fruits.txt | tr 'A' 'a' #Cambia las "a" por "A"
cat fruits.txt | tr 'A-Z' 'a-z' #El comando acepta rangos, esto cambiará todas las letras
cat fruits.txt | tr ' ' '.' #Cambiará los espacios por comas
cat fruits.txt | tr 'A-Z ' 'a-z.' #Combinación de las dos anteriores
#Por ejemplo:
echo Alexandre Viladot | tr 'A-Z ' 'a-z.' #Dará como resultado alex.viladot
cat fruits.txt | tr -d 'w' #Para borrar el patrón seleccionado
```
{% endcode %}
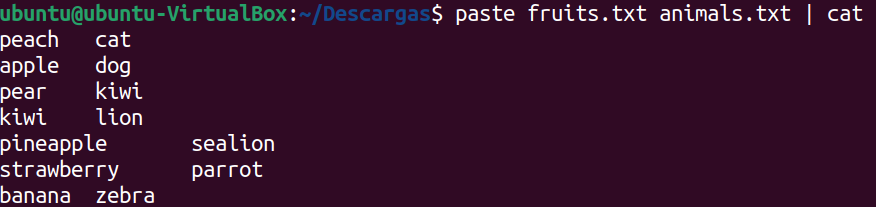
`paste` mezcla línea a línea dos archivos y el resultado lo muestra tabulado. Por ejemplo, si creamos un fichero de animales y lo juntamos con el de frutas el resultado será:
```bash
paste fruits.txt animals.txt
```
Resultado
`expand` es otro comando útil para cambiar tabulaciones por espacios. Al usarlo con el anterior el resultado es el siguiente:
```bash
paste fruits.txt animals.txt | expand -t 1
```
Donde `-t` se usa para especificar el número de espacios.
Resultado
`cut` es la herramienta principal para recortar caracteres o mostrar los campos que tu le pidas según un patrón establecido (`,` o `-` o una repetición de letras por ejemplo):
```bash
cut -c 2 fruits.txt #Recorta el segundo caracter de todas las lineas
cut -c 1-5 fruits.txt #Recorta todas las lineas a los primeros cinco caracteres
```
Quizás una de las funciones más interesantes es el delimitador:
#Partiendo de un csv, un archivo separado por comas, podemos seleccionar los campos que queramos
#Esto lo que haria seria mostrar los campos 1 y 2 del csv:
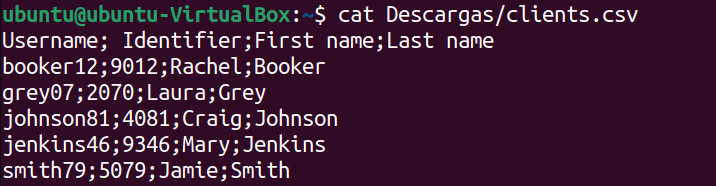
cut -d ";" -f 3,4 clients.csv
El *csv* es el siguiente:
clients.csv
Al aplicar el comando, el resultado es el siguiente:
Resultado
`split` es una utilidad que separa un archivo en paquetes lo cual puede ser útil para separar un archivo muy grande. El parámetro `-b` establece el tamaño máximo de los paquetes:
```bash
split -b 200M clients.csv
```
Ejemplo con split
Para practicar más comandos podemos trabajar con split, primero dividiremos un archivo en muchos paquetes (procura no pasarte):
```bash
split -b 20 clients.csv
```
En este ejemplo dividimos el archivo en paquetes de 20 Bytes
Vamos ahora a contar cuantos archivos ha creado:
```bash
ls -l | cut -d ' ' -f 11 | grep "x[a-z, A-Z][a-z,A-Z]\b" | wc -l
```
Podriamos volver a leer el archivo completo usando la wildcard con cat:
```bash
cat x[a-z][a-z]
```
Fíjate que `split` genera un montón de archivos llamados x— si queremos borrarlos podemos usar otra vez la *wildcard*:
```bash
rm x[a-z][a-z]
```
El último comando es el yes que sirve para repetir una palabra infinitamente:
```bash
yes "hola"
```
*(Imprimirá "hola" en cada línea hasta que lo interrumpas con `Ctrl + C`).*
También podemos:
* **Confirmar automáticamente una pregunta en un script:**
```bash
yes | rm -i archivo.txt
```
*(Simula que el usuario escribe "y" repetidamente, confirmando la eliminación).*
* **Generar un número limitado de líneas:**
```bash
yes "ifp" | head -n 10
```
*(Genera exactamente 10 líneas con la palabra "ifp").*
Caso práctico: Listado de correos
A partir del siguiente csv, vamos a generar un listado de correos usando los comandos aprendidos hasta ahora:
```
ID,Nombre,Edad,País,Empleos
1,Juan,25,México,Ingeniero
2,Ana,30,Argentina,Doctor
3,Luis,28,España,Abogado
4,Carla,22,Chile,Arquitecto
5,Pedro,35,Perú,Contador
6,María,30,México,Medico
7,Angel,24,España,Profesor
8,Aline,45,Chile,Abogado
9,Eduardo,79,México,Ingeniero
10,Galina,40,Perú,Medico
```
Queremos construir una lista que funcione como \@ifp\.com
Para ello vamos a construir una sentencia con "`paste`s"
```bash
cut -d ',' -f 2 #Nos devolverá el listado de nombres
cut -d ',' -f 4 #Nos devolverá el listado de empleos
yes "@ifp" | head -n $(wc -l < empleados.csv) #nos repetira la palabra tantas veces como filas tenga el csv
yes ".com" | head -n $(wc -l < empleados.csv)
| expand -t 1 | tr -d ' ' #Limpiamos los espacios y tabulaciones
```
Ahora construimos el comando teniendo en cuenta que paste admite dos parametros:
{% code overflow="wrap" %}
```bash
paste <(paste <(cut -d ',' -f2 empleados.csv) <(yes '@ifp' | head -n $(wc -l empleados.csv)) <(paste <(cut -d ',' -f4 empleados.csv) <(".com" | head -n $(wc -l empleados.csv))) | expand -t 1 | tr -d ' '
```
{% endcode %}
Ahora lo interesante seria hacer lo mismo pero con inicial.apellido:
```
// Some code
```
***
### Garantizar la integridad de los datos
Como ves, es muy fácil manipular archivos en Linux y eso puede ser un problema, por ejemplo, es posible que deseemos compartir un archivo con otra persona y queremos asegurar que el destinatario termina con una copia verdadera del archivo original. Un uso muy común de esta técnica se practica cuando los servidores de distribución de Linux alojan imágenes de CD o DVD descargables de su software junto con archivos que contienen los valores de **suma de comprobación** calculados de esas imágenes de disco.
{% hint style="info" %}
Una **suma de comprobación** es un valor derivado de un cálculo matemático, basado en una función hash criptográfica, contra un archivo. Existen diferentes tipos de funciones hash criptográficas que varían en intensidad. El examen espera que estés familiarizado con el uso de `md5sum`, `sha256sum` y `sha512sum`.
{% endhint %}
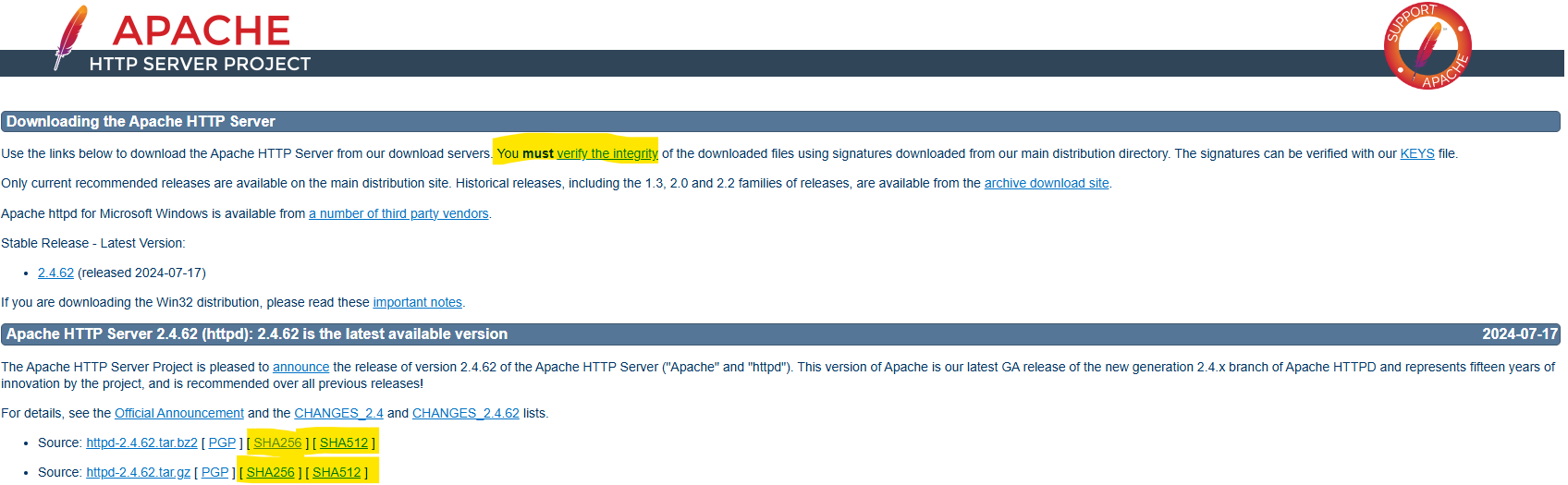
Pongamos el caso de apache2, si vamos a la [web de descarga](https://httpd.apache.org/download.cgi) veremos lo siguiente:
En amarillo está marcado la verificación
El **SHA256** del archivo lo obtenemos de la web directamente:
{% code fullWidth="true" %}
```bash
wget -O hash.txt https://downloads.apache.org/httpd/httpd-2.4.63.tar.bz2.sha256
#674188e7bf44ced82da8db522da946849e22080d73d16c93f7f4df89e25729ec *httpd-2.4.62.tar.bz2
```
{% endcode %}
Ahora descargamos el archivo en nuestro SO:
```bash
wget https://dlcdn.apache.org/httpd/httpd-2.4.63.tar.bz2
```
Vamos ahora con la comprobación:
```bash
#Creamos un archivo que contenga el valor:
sha256sum httpd-2.4.62.tar.bz2 > sha256-http.txt
#Podemos verificar el archivo directamente:
sha256sum -c sha256-http.txt
#Lo cual nos devolverá:
#httpd-2.4.62.tar.bz2: OK
```
Si tratáramos de alterar el archivo y volver a hacer la misma secuencia, este último comando fallaría.
También, por practicar, podríamos realizar el procedimiento de comprobación con el comando `diff` que comparará archivos línea por línea:
```bash
diff <(cut -d " " -f 1 hash.txt) <(cut -d " " -f 1 sumhash.txt)
```
* **`cut -d " " -f 1`**: Recorta solo el hash sin el nombre del archivo.
* **`diff <()`**: Se le pasa los hashes a diff.
Podriamos realizar esta misma sentencia con `vimdiff` para revisar los cambios caracter por caracter.
Lo mismo funciona con `md5sum` y `sha512sum` con sus respectivos hashes.
### Buscando más en los archivos
El comando *octal dump* (`od`) a menudo se usa para depurar scripts, aplicaciones y varios archivos. Hay varias opciones para el od, como la opción `-A` para controlar el radix de los desplazamientos de archivo o `-t` para controlar la forma del contenido del archivo presentado.
El radix puede ser especificado como `o`, (octal, el predeterminado), `d` (decimal), `x` (hexadecimal), o n (sin desplazamientos mostrados). Puedes mostrar el resultado como octal, hex, decimal, punto flotante, ASCII con escapes de barra inversa, o caracteres con nombre (`nl` para *newline* (\n), `ht` para *horizontal tab*, etc.).
Vamos a probar:
```bash
od fruits.txt
```
Resultado en octal
{% hint style="info" %}
La primera columna de salida es el desplazamiento de bytes para cada línea de salida. Como `od` imprime la información en formato octal de manera predeterminada, cada línea comienza con el desplazamiento de bytes de ocho bits, seguido de ocho columnas, cada una con el valor octal de los datos dentro de esa columna.
{% endhint %}
Para ver el contenido de un archivo en formato hexadecimal, usamos:
```bash
od -x fruits.txt
```
Resultado en hexadecimal
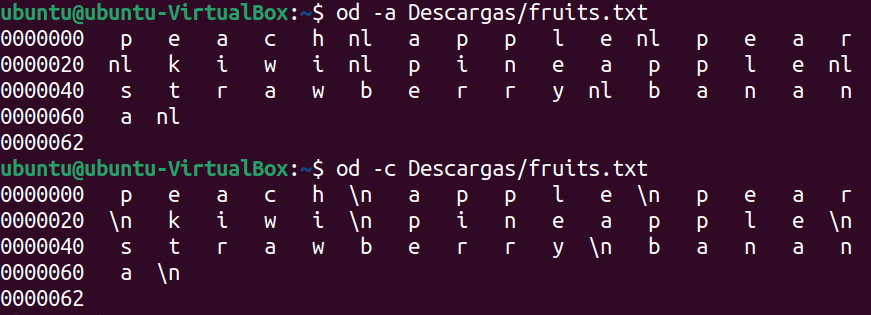
Para verlo en formato carácteres, mas leible usamos:
```bash
od -a fruits.txt #Para named characters
od -c fruits.txt #Para printable characters
```
Como ves, la diferencia se produce en aquellos caracteres especiales como el salto de línea en este caso.
Para omitir el desplazamiento de bytes:
```bash
od -An -c fruits.txt
```
Donde:
* `-A n`: No muestra las direcciones de memoria (evita la numeración de las líneas).
* `-c`: Muestra los caracteres imprimibles y representa los no imprimibles con secuencias especiales (ej. para nueva línea, para tabulación).
***
### Leer un archivo comprimido
Crearemos un archivo llamado `ftu.txt` que contenga una lista de los siguientes comandos:
Ahora usaremos el comando grep para imprimir todas las líneas que contienen la cadena `cat`:
```bash
cat ftu.txt | grep cat
#bzcat
#cat
#xzcat
#zcat
grep cat ftu.txt #Otra forma de hacerlo
#Para ver los que NO coinciden:
grep -v "cat" ftu.txt
#cut
#head
#less
#md5sum
#nl
#od
#paste
#sed
#sha256sum
#sha512sum
#sort
#split
#tail
#tr
#uniq
#wc
```
En el siguiente [topic](https://apuntes-alex.gitbook.io/apuntes-lpic-1/examen-101/103.3-administracion-basica-de-archivos#empaquetar-y-comprimir) veremos las diferencias y el funcionamiento de los archivos comprimidos, mientras te basta saber que estos sirven para concatenar o leer:
* `bzcat` para archivos comprimidos `bzip`
* `xzcat` para archivos comprimidos `xz`
* `zcat` para archivos comprimidos `gzip`
Ahora vamos a ver como leer los archivos:
```bash
gzip -v ftu.txt
#Esto creará un archivo ftu.txt.gz , el -v es para mostrar el progreso
#Para leerlo simplemente:
zcat ftu.txt.gz
```
***
### Los fundamentos de `sed`, el Editor de Stream
La mayor parte de lo que podemos hacer con grep también podemos hacerlo con `sed`, el editor de flujo para filtrar y transformar texto, para ello, primero recuperaremos nuestro archivo `ftu.txt` descomprimiendo nuestro archivo `gzip` del archivo:
```bash
gunzip ftu.txt.gz
ls ftu*
#Nos listará el archivo ftu.txt
#Ahora, podemos usar sed para listar solo las líneas que contienen la cadena cat:
sed -n /cat/p < ftu.txt
```
Dónde:
* El signo menor que `<` dirige el contenido del archivo ftu.txt a al comando sed.
* La palabra encerrada entre barras (es decir, `/cat/`) es el término que estamos buscando.
* **`/cat/`**: Especifica un patrón de búsqueda. En este caso, `cat` es el patrón que `sed` está buscando en el archivo. `sed` busca todas las líneas que contienen el texto "*cat*".
* **`p`**: Es el comando de impresión (*print*). Cuando `sed` encuentra una línea que coincide con el patrón `cat`, el comando `p` le indica a `sed` que imprima esa línea.
* La opción `-n` instruye a `sed` para que no imprima automáticamente cada línea del archivo a medida que es procesada. En otras palabras, silencia la salida por defecto.
De la misma forma que hacíamos con `grep -v` podemos realizar la búsqueda inversa con:
```bash
sed /cat/d < ftu.txt
```
Si no usamos la opción `-n`, sed imprimirá todo desde el archivo, excepto lo que la `d` indica a sed que elimine de su salida.
Un uso común de `sed` es buscar y reemplazar texto dentro de un archivo. Suponga que desea cambiar cada aparición de *cat* a *dog*. Puedes usar sed para hacer esto proporcionando la opción `s` para intercambiar cada instancia del primer término, *cat*, por el segundo término,
```bash
sed s/cat/dog/ < ftu.txt
```
{% tabs %}
{% tab title="Original" %}
```bash
cat ftu.txt
#bzcat
#cat
#cut
#head
#less
#md5sum
#nl
#od
#paste
#sed
#sha256sum
#sha512sum
#sort
#split
#tail
#tr
#uniq
#wc
#xzcat
#zcat
```
{% endtab %}
{% tab title="Cambiado" %}
```bash
cat ftu.txt
#bzdog
#dog
#cut
#head
#less
#md5sum
#nl
#od
#paste
#sed
#sha256sum
#sha512sum
#sort
#split
#tail
#tr
#uniq
#wc
#xzdog
#zdog
```
{% endtab %}
{% endtabs %}
Ahora, en lugar de utilizar `<` para pasar el archivo *ftu.txt*, podemos hacer que el comando opere directamente en el archivo. Por ejemplo, creamos simultáneamente una copia de seguridad del archivo original y operamos sobre el otro:
```bash
sed -i.backup s/cat/dog/ ftu.txt
ls ftu*
#Resultado: ftu.txt ftu.txt.backup
```
La opción `-i` realiza una operación `sed` directamente en el archivo original, si no pusiéramos el `.backup` después del parámetro `-i`, simplemente sobrescribiría su archivo original.
Algunos ejemplos más con sed:
* Para mostrar los usuarios del sistema y su shell de inicio de sesión predeterminado, escribirás:
```bash
sed -e 's/:.*:/:/' /etc/passwd
```
El comando de sustitución le indicará a *sed* que reemplace cualquier texto entre el primer y el último colon (:) de cada línea por un solo colon (:), eliminando efectivamente cualquier contenido entre los dos puntos del archivo original. El archivo original permanece sin cambios y la salida se envía a la salida estándar (la terminal).
* Para listar los últimos usuarios que iniciaron sesión, excepto `root`, escribirás:
```bash
last | sed '/^root /d'
```
Un uso muy común de *sed* es formar parte de una tubería. Aquí se usa para filtrar (utilizando el comando (d)elete ) todas las líneas que comienzan con la palabra `root` (`^` significa el inicio de la línea).
Más info: Caso Práctico: Análisis de Logs del Servidor Web
Vamos a ver un caso práctico en el que revisaremos varias cosas de un log de nginx, un servicio web, si ya tienes un servidor con nginx que se ha usado puedes obtener los Datos así:
```bash
tail -n 1000 /var/log/nginx/access.log > logs.txt
```
Cada línea en **logs.txt** tiene este formato:
```
192.168.1.10 - - [12/Mar/2024:10:20:30 +0000] "GET /index.html HTTP/1.1" 200 1024
203.0.113.45 - - [12/Mar/2024:10:21:15 +0000] "POST /login.php HTTP/1.1" 403 512
198.51.100.23 - - [12/Mar/2024:10:22:05 +0000] "GET /dashboard HTTP/1.1" 500 2048
```
Si no tienes nginx instalado, te dejo un log de ejemplo a continuación para que lo crees tu mismo en tu sistema:
{% code title="logs.txt" %}
```
192.168.1.10 - - [12/Mar/2024:10:20:30 +0000] "GET /index.html HTTP/1.1" 200 1024
203.0.113.45 - - [12/Mar/2024:10:21:15 +0000] "POST /login.php HTTP/1.1" 40 512
198.51.100.23 - - [12/Mar/2024:10:22:05 +0000] "GET /dashboard HTTP/1.1" 500 2048
192.168.1.12 - - [12/Mar/2024:10:23:10 +0000] "GET /contact.html HTTP/1.1" 200 768
10.0.0.5 - - [12/Mar/2024:10:24:45 +0000] "GET /about.html HTTP/1.1" 200 956
192.168.1.12 - - [12/Mar/2024:10:25:30 +0000] "POST /api/data HTTP/1.1" 201 300
192.168.1.10 - - [12/Mar/2024:10:26:05 +0000] "GET /index.html HTTP/1.1" 200 1024
203.0.113.45 - - [12/Mar/2024:10:27:50 +0000] "GET /admin HTTP/1.1" 40 512
198.51.100.23 - - [12/Mar/2024:10:28:20 +0000] "GET /dashboard HTTP/1.1" 200 2048
192.168.1.12 - - [12/Mar/2024:10:29:30 +0000] "GET /services.html HTTP/1.1" 200 700
10.0.0.5 - - [12/Mar/2024:10:30:40 +0000] "GET /about.html HTTP/1.1" 200 956
192.168.1.12 - - [12/Mar/2024:10:31:55 +0000] "GET /api/status HTTP/1.1" 500 400
192.168.1.10 - - [12/Mar/2024:10:32:15 +0000] "GET /index.html HTTP/1.1" 200 1024
203.0.113.45 - - [12/Mar/2024:10:33:25 +0000] "GET /admin HTTP/1.1" 403 512
198.51.100.23 - - [12/Mar/2024:10:34:45 +0000] "POST /dashboard HTTP/1.1" 200 2048
192.168.1.12 - - [12/Mar/2024:10:35:50 +0000] "GET /contact.html HTTP/1.1" 404 768
10.0.0.5 - - [12/Mar/2024:10:36:10 +0000] "GET /index.html HTTP/1.1" 200 956
172.16.0.8 - - [12/Mar/2024:10:37:20 +0000] "POST /api/login HTTP/1.1" 503 450
192.168.1.10 - - [12/Mar/2024:10:38:30 +0000] "GET /index.html HTTP/1.1" 200 1024
203.0.113.45 - - [12/Mar/2024:10:39:40 +0000] "GET /admin HTTP/1.1" 200 512
```
{% endcode %}
***
A continuación vamos a realizar una serie de acciones:
#### **1. Verificar el Tráfico de un Usuario Específico**
Para ver todas las solicitudes de la IP `192.168.1.12`:
```bash
grep '^192.168.1.12 ' logs.txt
```
Para buscar todas las respuestas 404:
```bash
grep '404' logs.txt
```
***
#### **2. Identificar las IPs con Más Accesos**
```bash
cut -d' ' -f1 logs.txt | sort | uniq -c | sort -nr | head -10
```
🔹 **Explicación:**
* `cut -d' ' -f1` → Extrae la primera columna (la IP).
* `sort` → Ordena las IPs.
* `uniq -c` → Cuenta repeticiones.
* `sort -nr` → Ordena de mayor a menor.
* `head -10` → Muestra las 10 IPs más frecuentes.
📌 **Salida esperada:**
```
150 192.168.1.10
120 203.0.113.45
100 198.51.100.23
```
***
#### **3. Filtrar Errores HTTP 4xx y 5xx**
```bash
grep 'HTTP/1.1" 4[0-9][0-9] ' logs.txt
grep 'HTTP/1.1" 5[0-9][0-9] ' logs.txt
```
🔹 **Explicación:**
* `grep 'HTTP/1.1" 4[0-9][0-9] '` → Busca códigos 4xx.
* `grep 'HTTP/1.1" 5[0-9][0-9] '` → Busca códigos 5xx.
📌 **Salida esperada (errores 4xx y 5xx):**
```
203.0.113.45 - - [12/Mar/2024:10:21:15 +0000] "POST /login.php HTTP/1.1" 403 512
198.51.100.23 - - [12/Mar/2024:10:22:05 +0000] "GET /dashboard HTTP/1.1" 500 2048
```
***
#### **4. Extraer las URLs Más Visitadas**